
Incident Post-Mortem: UK-B Network Event - 17:38, 14th April 2026

At Computle, we are transparent about our infrastructure and how we respond when things do not go to plan. At 17:38 on the 14th April 2026, a subset of customers at our UK-B facility experienced a network disruption lasting approximately 2 minutes, with a secondary issue affecting certain users until 19:00. This post explains what happened in detail, how we investigated it, and what we are doing to prevent recurrence.
Background: How UK-B Routing Works
Our UK-B facility uses a redundant pair of enterprise routers running OSPF for internal route synchronisation, and BGP upstream to three transit carriers (B4RN, Cogent, and NEOS). The two routers are connected by a pair of dedicated 25G fibre links (sfp28-9 and sfp28-10) running OSPFv2 in area 0 (the backbone). VRRP provides gateway redundancy for tenant networks, and each tenant has a pair of VyOS routers.
This is a standard dual-router, multi-homed design. Under normal operation, if one router loses an upstream carrier, OSPF and BGP reconverge within seconds and traffic fails over to the remaining paths.
How Customers Connect: Computle Gateway
Customers access their Computle Machines through Computle Gateway, which uses WireGuard to provide encrypted, always-on connectivity. All traffic between a customer's device and their virtual machines passes through a WireGuard tunnel, ensuring end-to-end encryption and tenant isolation.
This architecture is important context for understanding the impact of this event. WireGuard is a stateful protocol — each tunnel maintains a cryptographic handshake between the client and the gateway. When a network disruption interrupts a WireGuard tunnel, the tunnel does not resume instantly when connectivity returns. The client and gateway must complete a new handshake to re-establish the encrypted session. This typically takes 1–5 seconds depending on latency and client configuration, meaning customers may experience a slightly longer recovery time than the underlying routing protocols.
Network Isolation: Why Most Customers Were Unaffected
Our network plane architecture places every tenant within an isolated namespace using Carrier-Grade NAT (CGNAT) in the 100.x.x.x/10 range. Each tenant's machines and gateway devices are isolated from both the public internet and from other tenants. Traffic between tenants and external endpoints is routed through dedicated per-tenant gateway routers, powered by VyOS.
This isolation worked in our favour during this event. The ARP cache poisoning that caused the extended outage affected a forwarding path on the shared infrastructure subnet — not the tenant CGNAT namespaces themselves. As a result, the impact was contained to users whose traffic traversed the affected path, rather than the entire platform. The majority of users' WireGuard tunnels re-established within seconds of the OSPF reconvergence completing.
Dual-Router Redundancy: A Double-Edged Sword
The dual-router design exists to provide resilience — if one router fails, the other takes over via VRRP and OSPF. During this event, both routers remained operational throughout, and the redundancy design ensured that the initial OSPF disruption lasted less than two minutes.
However, it was also the dual-router design that created the conditions for the ARP cache poisoning. During the brief OSPF reconvergence window, both routers were simultaneously re-learning layer 2 adjacencies, and Router1 incorrectly cached a forwarding entry pointing to Router2 for a path that should have been handled locally. In a single-router design, this class of error cannot occur — but a single-router design offers no redundancy at all.
The remediation actions described below address this by disabling the proxy-ARP setting that prevented automatic recovery, and by isolating the gateway subnet so that cross-router ARP learning cannot occur in future.
The Disruption: 17:38–17:40
17:38:36 — First OSPF Adjacency Drop
At 17:38:36, both routers simultaneously declared the other unreachable on the sfp28-10 inter-router link. OSPF uses a dead interval of 40 seconds — meaning the last successful hello packet was exchanged at approximately 17:37:56.
Router1 logged the timeout from its perspective:
17:38:36 route,ospf,info ospf-instance-1 { version: 2 router-id: XXX }
ospf-area-1 { 0.0.0.0 }
interface { broadcast XXX%sfp28-10 }
neighbor { router-id: XXX state: Full } timeout
Router2 logged the same event:
17:38:36 route,ospf,info ospf-instance-1 { version: 2 router-id: 151.X.39.2 }
backbone-v2 { 0.0.0.0 }
interface { broadcast 151.243.39.14%sfp28-10 }
neighbor { router-id: 151.243.39.1 state: Full } state change to Init
state: Full } state change to Init— Router2 also lost the adjacency and reset to the Init state, the beginning of the OSPF neighbour state machine.
The second inter-router link (sfp28-9) remained stable throughout. OSPF adjacency on sfp28-9 was never lost. This tells us the issue was specific to the sfp28-10 path, not a general router failure.
17:38:36–17:38:46 — OSPF Reconverges
Both routers immediately began re-establishing the adjacency on sfp28-10. The OSPF state machine progressed through its standard sequence:
17:38:36 ... neighbor { state: Init } state change to TwoWay
17:38:36 ... neighbor election
17:38:36 ... state change to Backup DR
17:38:36 ... change DR: 151.243.39.2 BDR: me
17:38:36 ... neighbor { state: TwoWay } state change to ExStart
The exchange continued:
17:38:41 ... neighbor { state: ExStart } negotiation done
17:38:41 ... neighbor { state: ExStart } state change to Exchange
17:38:41 ... neighbor { state: Exchange } exchange lsdb size 43
17:38:46 ... neighbor { state: Exchange } exchange done
17:38:46 ... neighbor { state: Exchange } state change to Loading
17:38:46 ... neighbor { state: Loading } loading done
17:38:46 ... neighbor { state: Loading } state change to Full
17:38:26 — Second OSPF Flap
Fifty seconds after the first recovery, the same adjacency dropped again:
17:39:26 ... neighbor { router-id: 151.243.39.1 state: Full } state change to Init
The same recovery sequence occurred. During this second flap, a VRRP state change was observed on Router2:
17:39:34 vrrp,info vrrp61 now MASTER, master down timer
17:39:34 vrrp,info vrrp61 now BACKUP, got higher priority 250 from XXX
This VRRP transition lasted less than one second with OSPF recovering to Full by 17:28:36.
17:40:01— Telemetry System Engages Triage
A few moments later, telemetry systems observed packet loss and triggered our incident triage procedure. As no changes had taken place, we initially incorrectly classified this as a BGP network convergence event, as the symptoms suggested that a network path had gone down, and recovered. This was not the case, as I will explain later.
| Time (BST) | Event |
|---|---|
| 17:39 | Received timeout (no headers received) error — checked from Asia |
| 17:40 | Received "couldn't connect to server" error — checked from Europe |
| 17:40 | Received "couldn't connect to server" error — checked from North America |
| 17:40 | Waiting for 1 minute before starting the incident |
| 17:40 | Monitor recovered — North America |
| 17:40 | Received "couldn't connect to server" error — Asia |
| 17:41 | Incident started |
| 17:41 | Incident update posted to PagerDuty |
| 17:41 | Alerting triggered — email, SMS, push notification |
| 17:41 | Incident update posted to Microsoft Teams |
| 17:41 | Incident update posted to status page |
17:40:13 — BGP Session to NEOS Drops
The cumulative effect of the two OSPF flaps caused the iBGP session between the routers to briefly stall, which in turn caused the BGP HoldTimer to expire on the NEOS upstream session:
17:40:13 route,bgp,error HoldTimer expired NEOS-BGP-1
{l_addr: 161.12.105.135, r_addr: 161.12.105.134}
17:40:14 route,bgp,info NEOS-BGP-1
{l_addr: 161.12.105.135, r_addr: 161.12.105.134} Established
The other two upstream carriers (B4RN and Cogent) maintained their BGP sessions throughout the event, and at this point - 17:40 - all routing protocols were fully converged. At this stage, the vast majority of systems at UKB were operational with around 40 seconds of downtime.
SmokePing: Outbound Connectivity During the Event
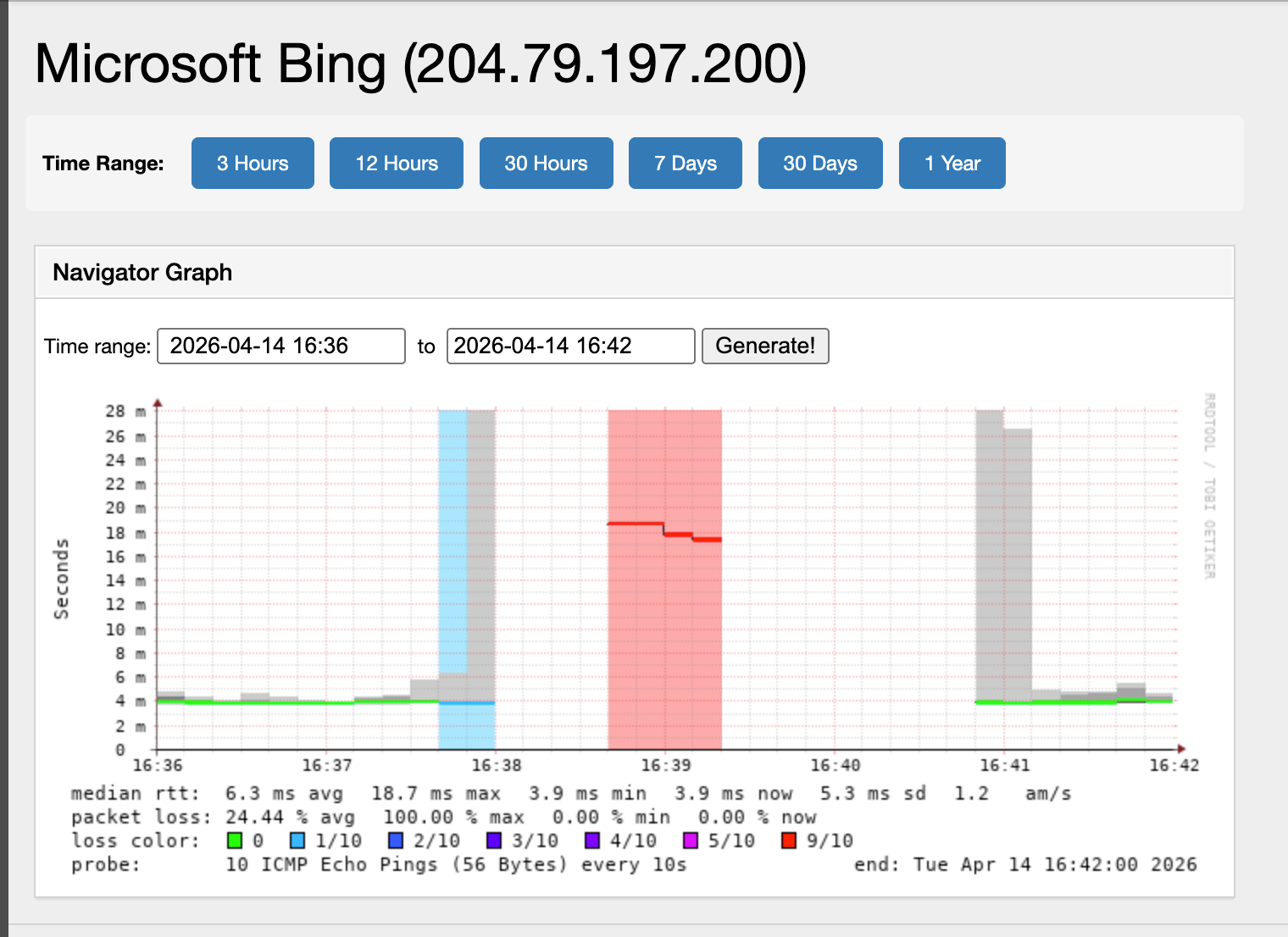
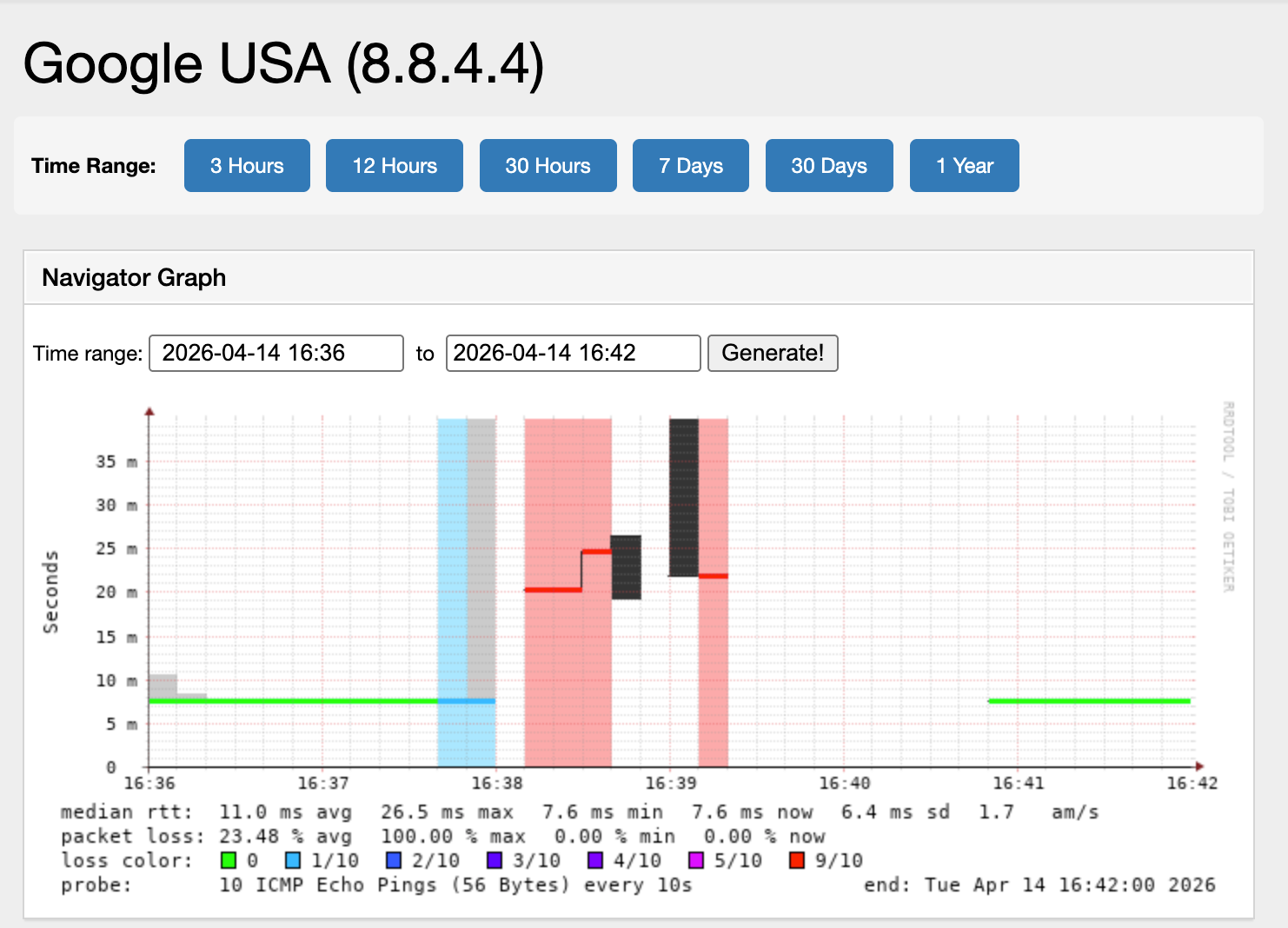
Our telemetry infrastructure continuously probes external targets from the UK-B network. The following graphs show the event window (17:36–17:42 BST), showing the two-minute distruption window:
Cloudflare DNS (1.1.1.1): Packet loss began at approximately 17:37:30, peaking at 100% at 17:38. Recovery was oberserved by 17:41.
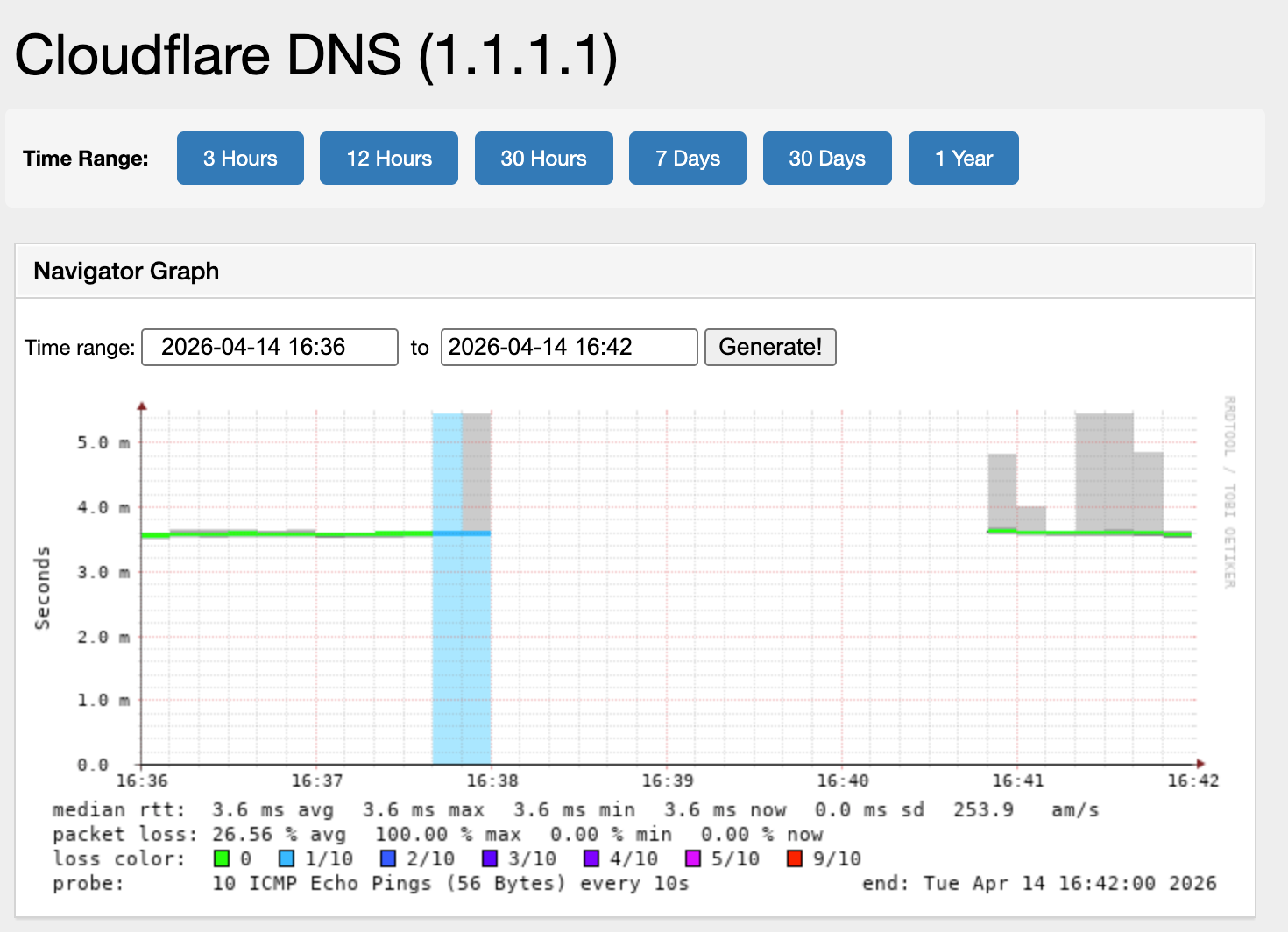
Microsoft Bing (204.79.197.200): Loss began at the same time, with RTT spiking from 4ms to 18ms during the event. 100% loss from 17:38:30 to 17:42:30.
Google USA (8.8.4.4): Loss began at 17:37:30 and recovered 3 minutes later.
Uptime Monitoring: Service-Level Impact
Our external uptime monitoring platform tracks all UK-B hosted gateways and services. The following table summarises the impact:
| UK-B Service | Duration |
|---|---|
| DCV Licensing | 0.46 seconds |
| Gateway VRRP (monitored tenant) | 0.83 seconds |
| Other monitored tenant gateways | No alert triggered |
| Core Router 1 | No alert triggered |
| Core Router 2 | No alert triggered |
| VRRP Virtual Gateways | No alert triggered |
| Cogent (carrier) | No alert triggered |
| B4RN (carrier) | No alert triggered |
| NEOS (carrier) | No alert triggered |
| Post-event clean up | ~50 minutes intermittent (ARP issue) |
DCV licensing recovered in under half a second. One monitored tenant gateway recorded a sub-second VRRP blip. All other monitored gateways and carrier links recorded zero downtime.
DCV Licensing (Primary): Downtime of 40 seconds.
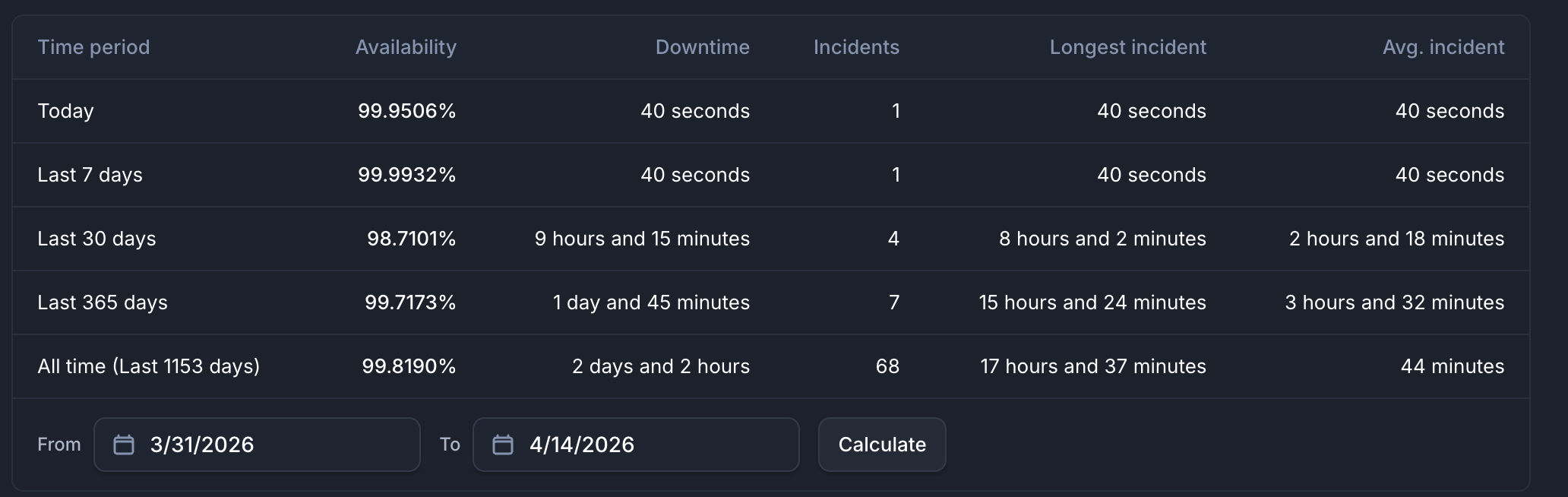
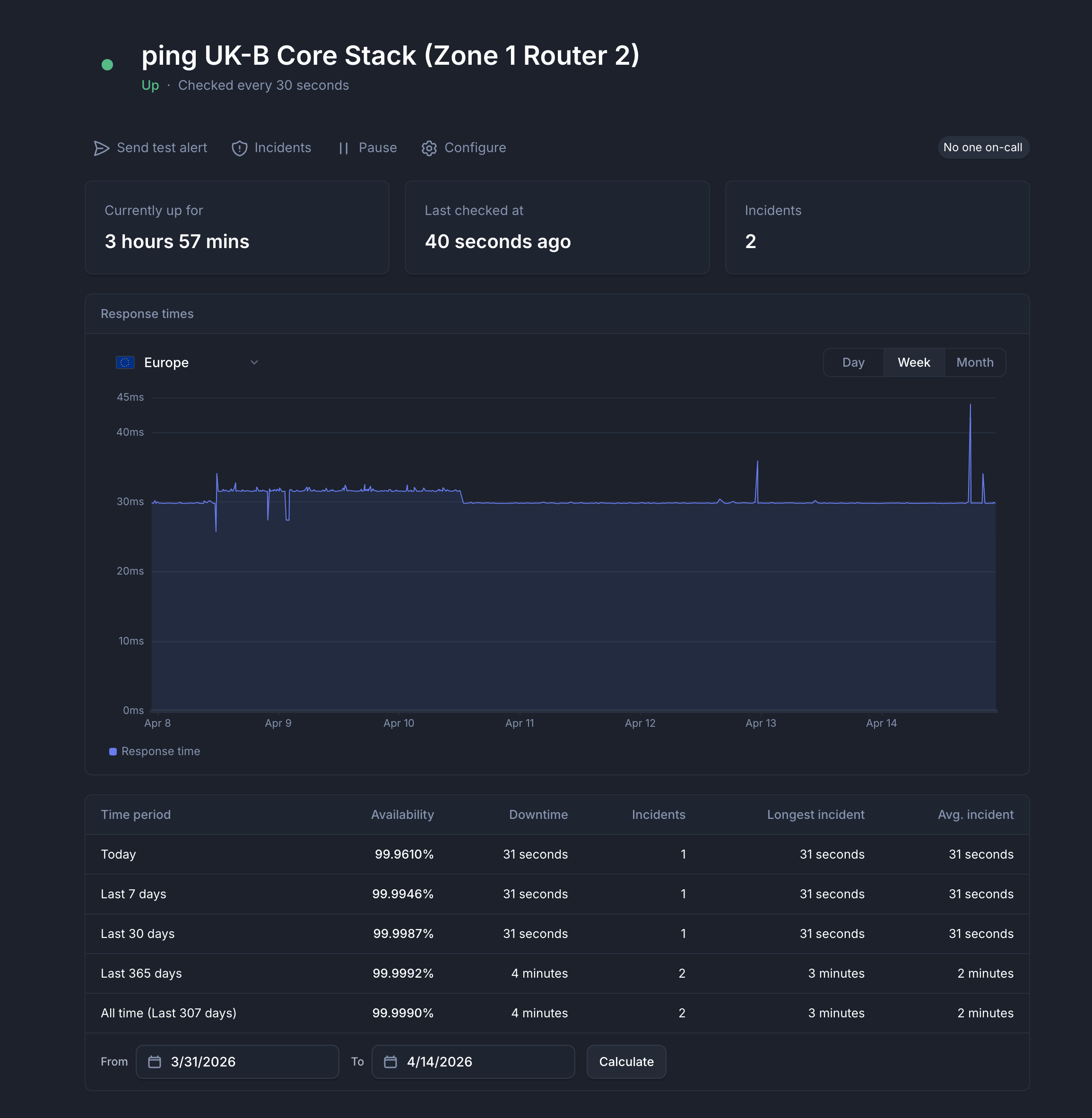
UKB Core Stack Zone 1 Router 2: Downtime of 31 seconds.
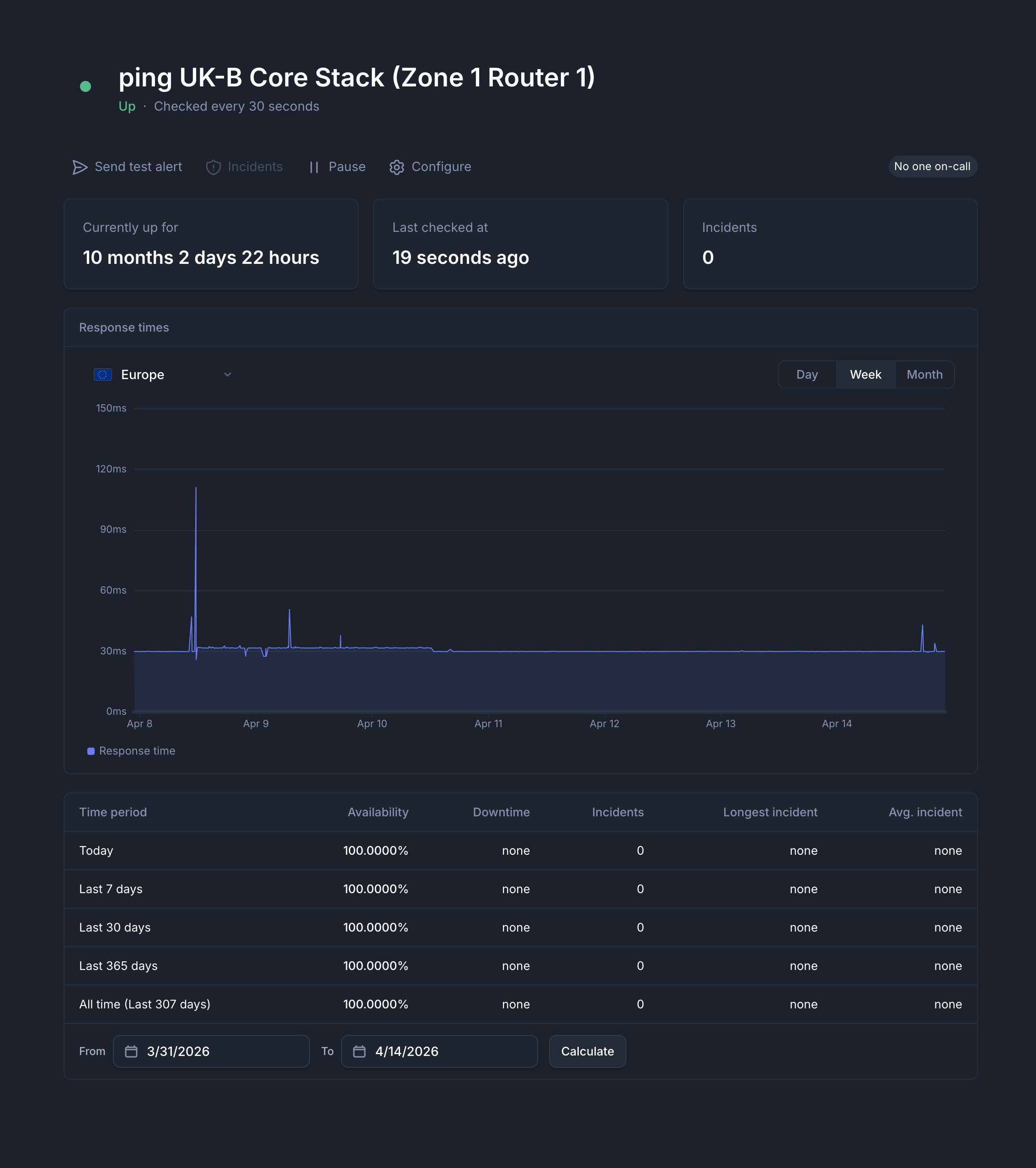
UKB Core Stack Zone 1 Router 1: Up for 10 months.
The only sustained impact was on a specific network path serving certain users. External monitoring detected intermittent connectivity failures on this path from 17:41 through to 18:48, confirming that the issue persisted long after routing protocols had fully converged. This was the path affected by the ARP cache poisoning described below.
Subset of Users Remain Affected: 17:40–19:00
A small number of users experienced connectivity issues due to a stale ARP cache entry silently misdirecting traffic. All routing protocols (BGP, OSPF, VRRP) appeared healthy and monitoring showed green throughout — the fault was invisible to standard health checks.
Investigation
Engineers began active investigation at 18:07. Users on the primary routing path were unaffected; only those routed through a redundant failover gateway lost internet access. The gateway itself was reachable, but all traffic to the internet was being dropped.
Packet captures revealed traffic was entering the bridge domain and being forwarded to the wrong interface rather than out to the upstream carrier. Checking the ARP table on the core router exposed the cause: two entries existed for the same IP — the correct tenant MAC, and an incorrect entry pointing to Router2's MAC, learned during the OSPF reconvergence window earlier in the incident.
Resolution
The stale ARP entry was manually removed, restoring service for the impacted users.
What We Are Doing
Inter-router link investigation
We are continuing to investigate the root cause of the OSPF packet loss on sfp28-10 that initiated the event. We are reviewing the physical layer and switching infrastructure on this path to prevent recurrence.
Disabling proxy-ARP
The proxy-ARP setting on the core bridge interface is being removed. This is the direct cause of the extended outage — it caused the secondary router to continuously re-poison the ARP cache every 30 seconds, preventing automatic recovery.
Inter-router subnet isolation
We are evaluating moving the inter-router link addresses and iBGP loopbacks to a separate address block from the tenant IP blocks, removing the routing condition that allowed proxy-ARP to respond to tenant ARP requests in the first place.
Enhanced monitoring
We are implementing:
- Alerting on duplicate ARP entries for the same IP across multiple interfaces
- OSPF neighbour state change notifications with sub-minute response targets
- Periodic ARP table audits comparing expected MAC bindings against actual entries
Gateway health-aware failover
During this event, the affected gateway continued to advertise itself as the active VRRP master and accept user traffic, despite being unable to forward that traffic to the internet. The gateway's VRRP health was based solely on interface state and peer visibility — it had no awareness of whether outbound connectivity was actually working.
We are evaluating the addition of outbound reachability health checks to tenant gateway routers. These checks would allow a gateway to detect that its outbound path is broken and automatically lower its VRRP priority, causing users to fail over to the standby gateway. Had this been in place during this event, affected users would have been moved to a working path significantly faster.
Closing
We understand that any period of downtime has a real impact on the people who depend on our platform to do their work. For the majority of customers at UK-B, the disruption lasted approximately 2 minutes while routing protocols reconverged, with WireGuard tunnel re-establishment adding a further few seconds. A smaller number of customers experienced an extended impact due to a layer 2 condition that was invisible to our standard monitoring and required manual packet-level investigation to identify and resolve.
Neither duration is acceptable to us. The initial disruption exposed a gap in our inter-router link resilience that we are actively investigating. The extended impact was caused by a proxy-ARP configuration that prevented automatic recovery, and we are working to remedy this design.
We apologise for the disruption and thank our customers for their patience.



